Data residency enables the user to follow the law and regulations for keeping local data local. It refers to the physical or geographic location where an organisation chooses to store or process regulated data.
In this article we will demonstrate using an example of how we can provide data residency with pgEdge using table partitioning. The diagram below show a two node pgEdge cluster containing partitioned tables, in order to provide data residency for local data, some of the partitioned won't be added to the replication set while others will be part of the replication set.
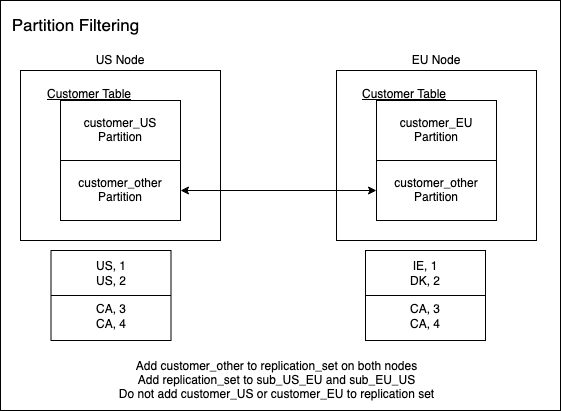
Add one partition to replication
./ctl spock repset-add-table bmsql_customer
./ctl spock repset-add-partition bmsql_customer demo --partition bmsql_customer_other
An additional row filter can be used here. Check the Row filtering section below for information on how to use the --row_filter flag.
Remove is similar:
./ctl spock repset-remove-partition bmsql_customer demo --partition bmsql_customer_other
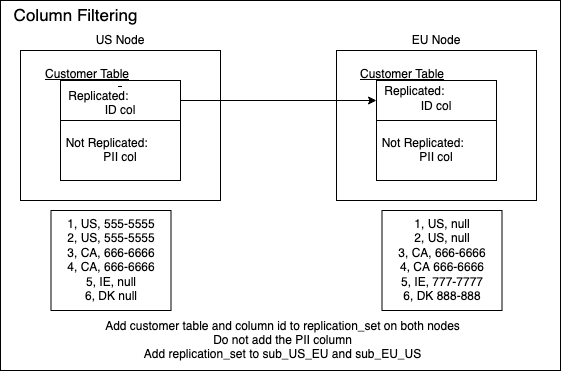
The bmsql_customer table in benchmarkSQL has some PII columns, c_last, c_first, c_middle, c_phone, etc. To filter out these columns, use the following commands to add only the columns you want.
This command will add the bmsql_customer table to the demo_repset replication set, but only include the columns listed
./ctl spock repset-add-table demo_repset bmsql_customer demo --columns 'c_w_id, c_d_id, c_id, c_discount, c_ytd_payment, c_payment_cnt, c_delivery_cnt, c_since, c_credit, c_credit_lim, c_balance, c_city , c_state, c_zip, c_location, c_country'
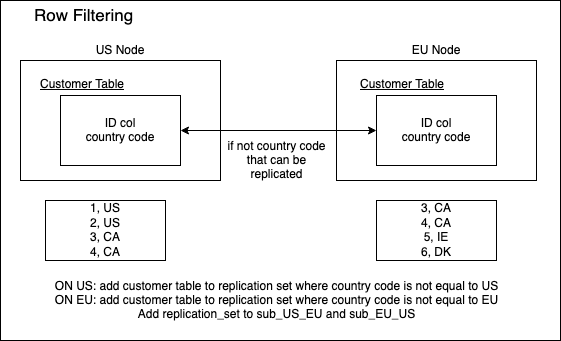
./ctl spock repset-add-table demo_replication_set "foo_rowfilter_test" demo --row_filter "usage_code = ''ABC''"
This article was submitted by Cady Motyka with minor changes from Ahsan.