How to setup pgEdge for doing cluster monitoring with Prometheus and Grafana.
- First, let’s set up a Postgres metrics exporter that can export to a Prometheus instance.
- Download the latest release of the postgres exporter from here. Specify the DSN of the database instance it needs to scrape metrics from and run:
|
export DATA_SOURCE_USER=<database_user> |
- Replace <database_user> with the appropriate username, and make changes as needed to the DATA_SOURCE_URI and the DATA_SOURCE_PASS_FILE.
- Starting the postgres exporter will create an HTTP server that listens on 9187 (by default), and metrics can be later scraped by Prometheus on <host>:9187/metrics.
- You will need to repeat steps 1-3 for each node in the pgEdge cluster.
- Now, let’s set up sql_exporter for exporting the results of custom queries. We primarily use this to export spock-related metrics into the dashboard.
- Download sql_exporter from here, and use this for the config file:
|
jobs: |
- Replace <n1_dsn> with the actual DSN needed to connect to n1. Similarly, replace the DSN for n2, n3 and so on. Naming the targets is important here since the dashboard relies on target names to display metrics. For example, the DSNs could look something like this:
|
- targets: |
- Once the config file is updated, run:
|
./sql_exporter |
- Starting the sql_exporter will create an HTTP server listening on 9399 (by default).
Note: You will need only one instance of sql_exporter for all your nodes. Unlike the postgres exporter, you do not need to install it on each pgEdge node.
- Next, we need an instance of Prometheus. Download it from here, and use this as the config file:
|
# my global config |
- The targets specify the nodes to connect to and scrape metrics from. In our example, our nodes are n1, n2 and n3, and their respective instances of postgres exporters are running on n1:9187, n2:9187 and n3:9187. The sql_exporter is running on n1:9399.
- After making necessary changes to the config file, start Prometheus by:
|
./prometheus --config.file=prometheus.yml |
- This will start the Prometheus server on <host>:9090
- Note: We strongly recommend having friendly node names, such as n1, n2, etc., for the nodes. You can modify the /etc/hosts file on each of the nodes to ensure that the friendly node names correctly point to the appropriate IP addresses or domain names.
- Finally, we will need an instance of Grafana for the metrics scraped by our Prometheus instance.
- Download and install Grafana from here. Starting grafana-server should start the dashboard at <host>:3000. Go through the setup and then add Prometheus as the data source. You can follow this tutorial for setting up the data source.
- Make sure that the Prometheus server URL correctly points to the instance we created earlier. It should look something like this:
|
http://n1:9090 |
- Finally, let’s import our dashboard into Grafana. Download the dashboard template from here.
- Click on the left panel -> Dashboards -> New -> Import
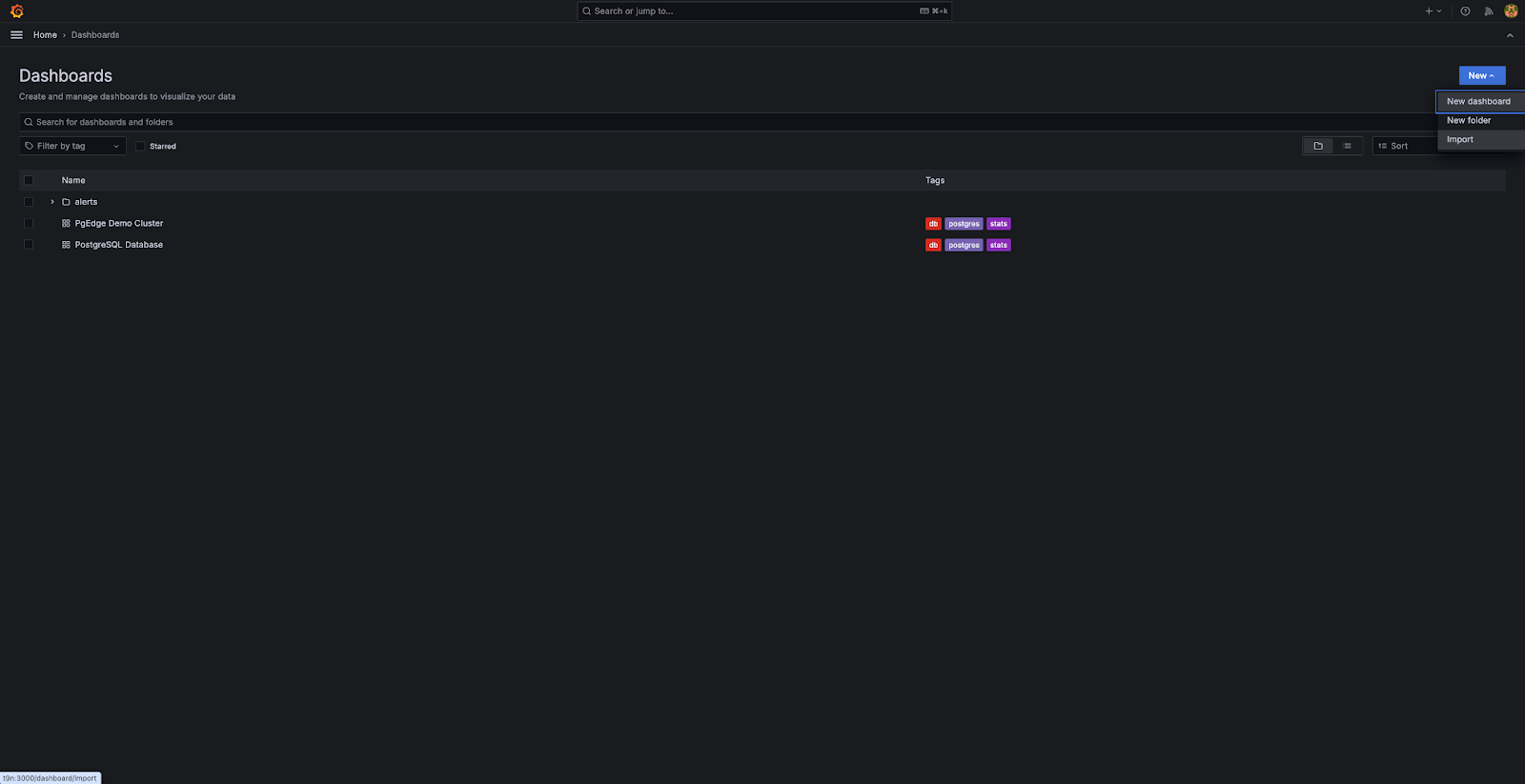
- Upload or paste the dashboard JSON downloaded previously. You should now have the dashboard ready with metrics, and it should look something like this:
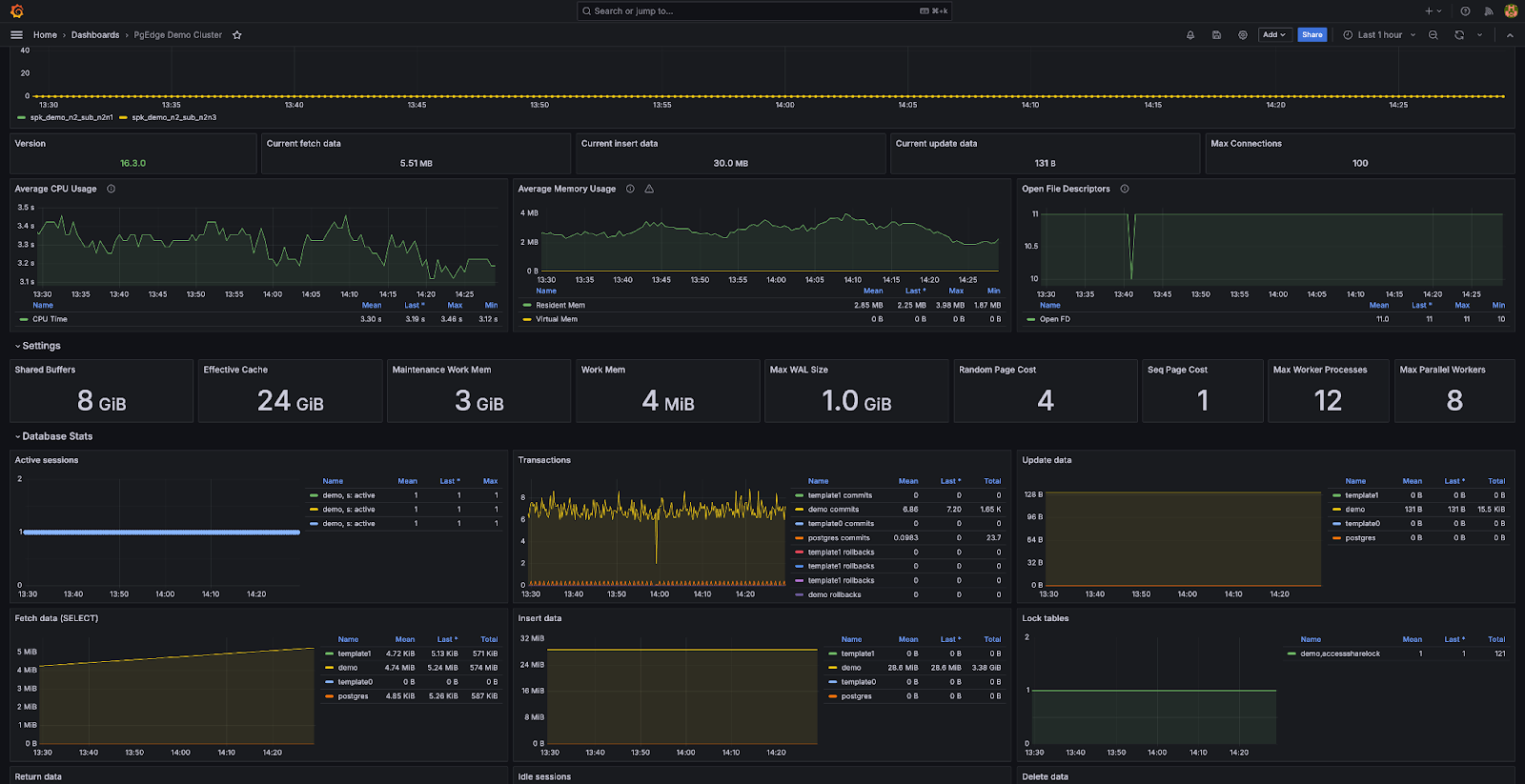
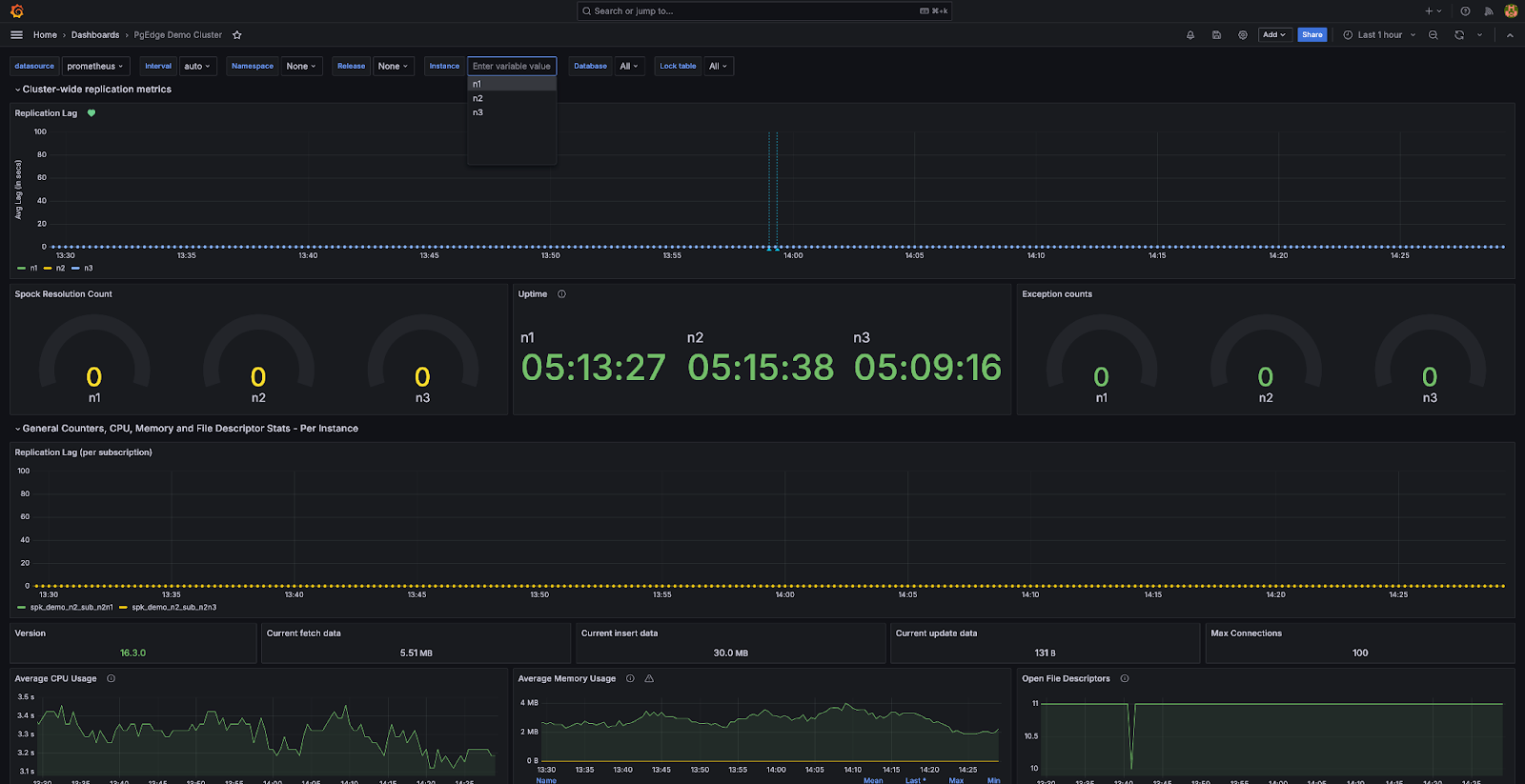
- Cluster-wide metrics are displayed in the first section of the dashboard, and instance-specific metrics are displayed in the sections following that. You can change the instance you want to look at using the ‘Instance’ dropdown at the top of the dashboard; like so: